引言
现在应用最好的一个领域就是基于视频图像的应用,尤其是基于深度卷积神经网络在视频图像领域的应用最为火热。安防是 技术最好的实践领域,安防每天产生的全天候的海量视频图像数据为 提供了最佳实践基础。
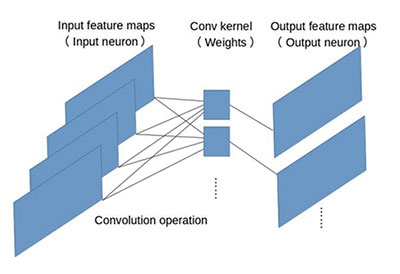
图1 安防 应用三大基础
除了海量数据、深度卷积神经网络算法,还有GPU 或神经网络硬件加速引擎也在快速安防应用领域广泛应用。海量视频图像、深度神经网络算法、GPU 或深度神经网络硬件加速器,这三者共同推动者 在安防领域的实践,如图1所示。其中GPU 和深度神经网络加速器的发展驱动力来自于深度神经网络算法的发展。所以在这三者中,深度神经网络算法的发展是核心,它决定着深度神经网络硬件平台的发展,同时也关系着视频图像进行标注行为。所以本文着重从深度神经网络算法的角度,介绍 在安防领域的实践应用。
深度卷积神经网络发展
最早的卷积神经网络模型(比如LeNet和AlexNet)很是简单,如图2所示,使用堆栈式(stack)单卷积或者多卷积加单池化(pooling)的结构,卷积层做特征提取,池化层进行空间下采样。输入特征映射(inputfeature maps), 即输入神经元(inputneurons)经过带有权值(weights)的卷积核(conv kernel)进行多维卷积,在输出神经元(output neurons)上得到输出特征映射(outputfeature maps)。
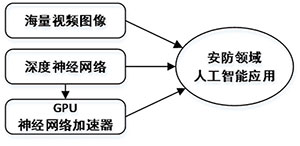
图2 简单卷积网络
之后的卷积神经网络版本,融合了Network In Network 来增加隐层提升非线性表达,它使用1x1卷积映射到隐含空间,再在隐含空间做卷积。同时考虑到多尺度,在单层卷积层中用多个不同大小的卷积核来卷积,最后把结果串联起来得到输出特征映射。这一结构,被称之为“Incepti on”,由谷歌提出,如图3所示,代表模式有Inception-v1、Inception-v2、Inception-v3、Inception-v4等版本。
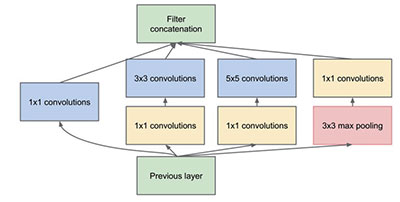
图3 Inception模块
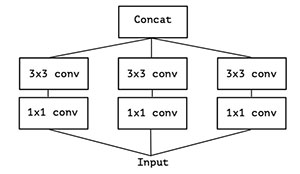
图4 简化版Inception
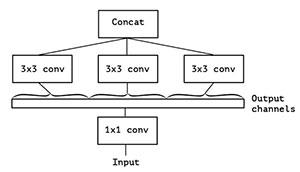
图5 简化版Inception另一种描述方式
逐层可分离卷积(Depthwise SeparableConvolution)可以认为是Inception 的扩展,它是Inception 结构的极限版本,如图4所示,一个简化版本的Inception,我们可以看做一整个输入做1x1卷积,然后切成三段,分别进行3x3卷积后相连,如图5所示。图4和图5两个形式是等价的,即Inception 的简化版本又可以用如下形式表达:
假若不是分成三段,而是分成五段或者更多,那模型的表达能力是不是更强呢?于是我们就切更多段,一直切到不能再切为止,此时正好是输出通道(output channels)的数量(极限版本),如图6所示:
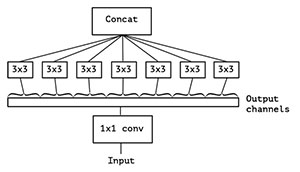
图6 Inception极限版本
这就是逐层卷积(depthwise convolution),逐层卷积是对输入的每一个通道(channel)独立的用对应通道的所有卷积核去卷积,假设卷积核的形状是filter_height*filter_width*in_channels* channel_multiplier,那么每个输入通道(in_channel)会输出channel_multiplier 个通道,最后的特征映射面(feature map)就会有in_channels *channel_multiplier 个通道。反观普通的卷积,输出的特征映射面一般就只有channel_multiplier 那么多个通道。
在图像分割领域,图像输入到深度卷积神经网络中,先对图像做卷积再池化(即下采样),降低图像尺寸的同时增大感受野,但是由于图像分割预测是逐个像素输出的,所以要将池化后较小尺寸的图像上采样到原始图像尺寸进行预测。上采样一般采用反卷积(deconv)操作,使得每个像素预测都能看到较大感受野。因此图像分割卷积神经网络中有两个关键,一个是池化减小图像尺寸增大感受野,另一个是上采样扩大图像尺寸。在先减小再增大尺寸的过程中,就会有信息损失。所以就设计出一种新的操作:空洞卷积(dilated conv)或者卷积核膨胀,即不通过池化也能有较大的感受野,如图7所示。
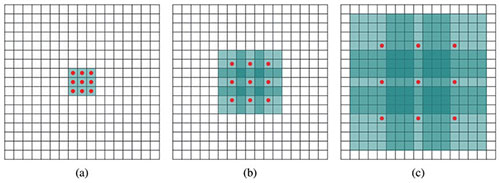
图7 空洞卷积
图7中的(a) 图对应3x3的1-dilatedconv,和普通的卷积操作一样,(b) 图对应3x3的2-dilated conv,实际的卷积核尺寸还是3x3,但是空洞为1,也就是对于一个7x7的图像块,只有9个红色的点和3x3的卷积核进行卷积操作,其余的点(绿色点)略过。也可以理解为卷积核的尺寸实际为7x7,但是只有图(b) 中的9个点的权重不为0,其余都为0。 可以看到虽然卷积核尺寸只有3x3,但是这个卷积的感受野已经增大到了7x7。(c) 图是4-dilated conv 操作,能达到15x15的感受野。空洞卷积的好处是不做池化带来损失信息的情况下,加大了感受野,让每个卷积输出都包含较大范围的信息。
还有一种卷积神经网络称为可形变卷积(Deformable convolutions)神经网络,其思想很巧妙:它认为规则形状的卷积核(比如一般用的正方形3x3卷积)可能会限制特征的提取,如果赋予卷积核形变的特性,让神经网络根据标注标签反向传播回来的误差自动的调整卷积核的形状,适应网络重点关注的感兴趣的区域,就可以提取更好的特征。如图8所示,神经网络会根据原位置(a),学习一个偏移量,得到新的卷积像素点位置(b) 图,那么一些特殊情况就会成为这个更泛化的模型的特例,例如图(b) 中图表示从不同尺度物体的识别,图(b) 右图表示旋转物体的识别。
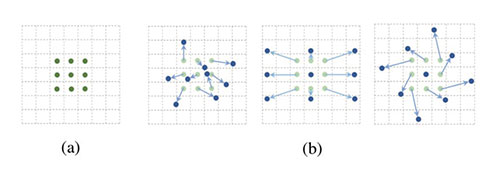
图8 变形卷积
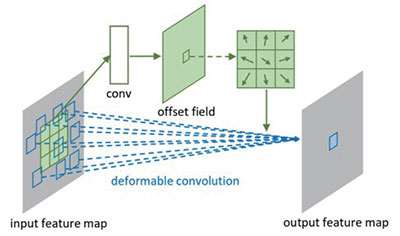
图9 变形卷积
这个思想的实现方法也很常规,上图9中包含两处卷积,第一处是获取偏移(offsets)的卷积,即我们对输入特征映射面(inputfeature map)做卷积,得到一个输出(offsetfield),然后再在这个输出上取对应位置的一组值作为偏移。假设输入特征映射面的形状为batch*height*width*channels,我们指定输出通道变成两倍,卷积得到的偏移域(offset field) 就是batch*height*width*2×channels。为什么指定通道变成两倍呢?因为我们需要在这个偏移域里面取一组卷积核的偏移,而一个偏移肯定不能一个值就表示的,最少也要用两个值(x方向上的偏移和y 方向上的偏移)所以,如果我们的卷积核是3x3,那意味着我们需要3x3个偏移,一共需要2x3x3个值。取完了这些值,就可以顺利使卷积核形变了。第二处就是使用变形的卷积核来卷积,这个比较常规。
还有一种卷积神经网络称为“特征重标定卷积神经网络”,这个卷积是对特征维度作改进的。一个卷积层中往往有数以千计的卷积核,而且我们知道卷积核对应了特征,可是那么多特征要怎样区分呢?这种网络就是通过学习的方式来自动获取到每个特征通道的重要程度,然后依照计算出来的重要程度去提升有用的特征并抑制对当前任务用处不大的特征。如图10所示,首先做普通的卷积,得到了输出特征映射面(output feature map),它的形状为C*H*W,这个特征映射面的特征很混乱。然后为了获得重要性的评价指标,直接对这个特征映射面进行全局平均池化,就得到了长度为C的向量。然后对这个向量加两个全连接层,做非线性映射,这两个全连接层的参数,也就是网络需要额外学习的参数。最后输出的向量,我们可以看做特征的重要性程度,然后与特征映射面对应通道相乘就得到特征有序的特征映射面了。
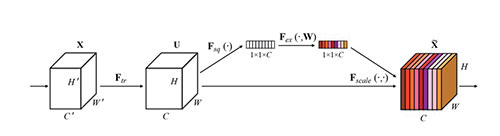
图10 特征重标定卷积神经网络Squeeze-and-Excitation模块
2017年6月,宇视科技(uniview)与英特尔(intel)联合发布VDC12500系列视图数据中心一体机『昆仑二代』,采用融合业务架构,支持CPU 通用计算板卡、GPU 计算板卡混插,实现通用计算业务、智能分析业务、大数据业务,广泛应用于 城市的建设:一台可并发处理2.4亿大库智能搜索、或200亿人车物的结构化数据分析、或8亿数据秒级“以图搜索”应用,具备强劲的高并发处理能力和集群化管理能力。
昆仑二代高性能专用计算平台,插CPU 板卡可进行海量数据的处理,能够快速存储和索引,多种数据进行时空碰撞;插GPU 板卡则继承全部昆仑一代的智能分析功能。昆仑二代=CPU 通用计算+ 大数据内存计算+GPU 智能计算,实现视频调度、大数据、智能等全部安防算力的融合。

图11 英特尔助力昆仑二次进化,成为高性能专用计算平台,采用弹性可扩展硬件架构,未来可以持续升级
总结
现在越来越多的卷积神经网络模型从巨型网络到轻量化网络一步步演变,模型准确率也越来越高。当前 实践中追求的重点已经不只是准确率的提升,更都聚焦于速度与准确率的平衡,都希望模型又快又准。因此从原来AlexNet、VGGNet,到体积小一点的Inception、ResNet 系列,到目前能移植到移动端的MobileNet、ShuffleNet,我们可以看到这样一些趋势:
卷积核方面:
◆ 大卷积核用多个小卷积核代替;
◆ 单一尺寸卷积核用多尺寸卷积核代替;
◆ 固定形状卷积核趋于使用可变形卷积核;
◆ 使用1×1 卷积核。
卷积层通道方面:
◆ 标准卷积用逐层卷积代替;
◆ 使用分组卷积;
◆ 分组卷积前使用通道重组(channel
shuffle);
◆ 通道加权计算。
卷积层连接方面:
◆ 使用忽略连接(skip connection),让模型更深;
◆ 稠密连接(densely connection),使每一层都融合上其它层的特征输出(DenseNet)
由此可见,应用于安防领域的 中的深度卷积神经网络模型结构,研究领域为了更快、更准的检测识别目标,一直在持续更新模型结构,由此也带来了安防应用的不断推陈出新。
杰夫• 辛顿(Geoffrey Hinton,1947-),以“深度学习之父”和“神经网络先驱”闻名于世,其对深度学习及神经网络的诸多核心算法和结构(包括“深度学习”这个名称本身,反向传播算法,受限玻尔兹曼机,深度置信网络,对比散度算法,ReLU 激活单元,Dropout 防止过拟合,以及深度学习早期在语音方面突破)做出了基础性的贡献。他近几年以“卷积神经网络有什么问题?”为主题做了多场报道,提出了胶囊(Capsule)计划。Hinton 似乎毫不掩饰要推翻自己盼了30多年时间才建立起来的深度学习帝国的想法,他根据神经解剖学、认知神经科学、计算机图形学的启发,对卷积神经网络产生了动摇。他的这种精神也获得了同行李飞飞(ImageNet 创始者)等人肯定。
这标志着 算法并没有完全成熟起来,虽然现在在安防领域得到大量应用,但每种应用并不是很完美。这种不完美既有工程实践问题,更有理论模型问题。在未来的 应用道路上,卷积神经网络或者只是一个暂时的表现很优秀的算法,将来必将会出现更加优秀的算法。
参考文献
[1]https://zhuanlan.zhihu.com/p/29367273
[2]http://prlab.tudelft.nl/sites/default/files/Deformable_CNN.pdf
[3]https://arxiv.org/pdf/1610.02357.pdf
[4]https://zhuanlan.zhihu.com/p/28749411
[4]https://zhuanlan.zhihu.com/p/29435406
 浙公网安备
33010802004032号
浙公网安备
33010802004032号

