(artificial intelligence)[1],按照维基百科定义,指由人工制造出来的系统所表现出来的智能。这里的人工制造的系统,具体到安防领域,指的就是智能算法。其实现在安防领域中的大多数设备,比如支持移动侦测的IPC、智能分析服务器、视频浓缩和视频摘要服务器、非现场执法设备、卡口型摄像机,等等,都实现着 算法。所以, 应用于安防领域,并不是一个新鲜话题。
学科主要研究算法的以下几个方面的能力:演绎(deduction)和推理(reasoning)、知识表示(knowledgerepresentation)、规划(planning)、学习(learning)、自然语言处理(naturallanguage processing)、运动和控制(motionand manipulation)、感知(perception)、社交智能(social intelligence)、创造力(creativity)、通用智能(generalintelligence)。
学科主要的研究方法有:控制论和脑模拟(cybernetics and brainsimulation),符号法(symbolic):又含有认知模拟(cognitive simulation)法、基于逻辑(logic-based)法、基于知识(knowledgebased)法、子符号(sub-symbolic)法、统计学(statistical)法、集成方法(Integratingthe approaches)。
学科主要的工具有:搜索和优化(search and optimization)、逻辑(logic)、不确定推理的概率法(probabilisticmethods for uncertain reasoning)、分类和统计学习法(classifiers and statisticallearning methods)、神经网络(Neuralnetworks)、深度前馈神经网络(deepfeedforward neural networks)、深度递归神经网络(deep recurrent neuralnetworks)、控制论(control theory)。
深度学习兴起
2012年,多伦多大学Geoff Hinton的两个博士生Alex Krizhevsky 和IlyaSutskever 在NIPS 上发表论文《ImageNetClassification with Deep ConvolutionalNeural Networks》[2],采用深度卷积网络算法,在图片分类竞赛ImageNet 中的大规模视觉识别挑战赛ILSVRC-2010和ILSVRC-2012上(如图1和图2所示),图片分类结果均拿到了第一名,并且相比于传统的手工特征的最好的算法(SIFT+Fisher Vectors)的分类结果(top-1错误率和top 错误率)减少近10% !(注图1和图2中斜体为最好的手工特征算法结果,粗体为CNN 结果,带星号的为神经网络结构经过“预训练”了的分类结果)要知道,在过去竞赛中,使用传统手工特征的形形色色算法的结果提升幅度从没有这么高。可想而知,这在计算机视觉(computer vision)领域引起地震。同时也拉开了CNN 在计算机视觉领域以及其他领域大量运用,以及CNN网络结构快速发展的大幕。
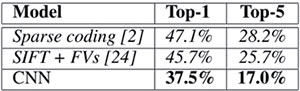
图1 引文[2]中的ILSVRC-2010中的DCNN和传统手工特征算法图片分类结果对比
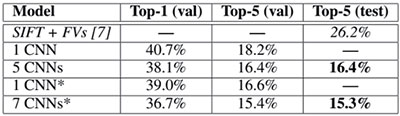
图2 引文[2]中的ILSVRC-2012中的DCNN和最好的传统手工特征算法图片分类结果对比
卷积神经网络并不是个新鲜算法,在20世纪曾经经历过一段时期的冷遇,根因是卷积神经网络训练过程收敛前需要反复迭代前向传播和反向传播,计算量超多,使用现在速度最快的多核CPU 架构,训练时间也要几十天。NVIDIA 的GPU 中的数以千计的计算单元阵列的快速发展有效的解决了这一问题,大大缩短了训练周期。如图3所示为论文中使用的CNN 训练结构,该网络人们习惯上称为AlexNet。
同时随着网络中的连接数(参数)的增多,需要的训练数据也越多,比如ImageNetLSVRC-2010就含有1000多个种类的120多万张的图片。
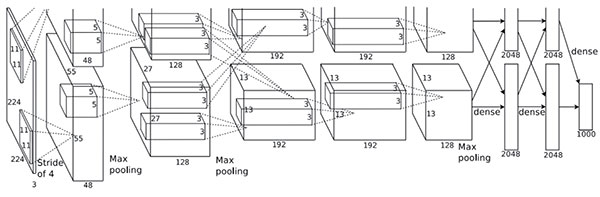
图3引文[2]使用的由两个GPU分担的CNN结构图
由此可见,GPU 的高速发展以及海量数据的出现,使得深度神经网络训练变得可行,加速了深度神经网络在计算机视觉、语音、文本、自然语言处理等领域的快速普及。
深度学习是机器学习的一个分支。机器学习的目的是根据在训练数据集上每个样本的目标值,学习得到一个模型。训练时,对分类器输出和目标值进行对比,根据使用的分类器和代价函数(或损失函数,lossfunction),使用优化算法,反复迭代,不断调整参数,直到算法收敛为止。检测时使用该模型用于新的样本,模型的输出就是我们需要的输出。如图4所示。相比于检测过程(或测试过程),训练过程需要反复迭代,运算量极大。传统手工设计特征的表现能力远远不及神经网络的抽象表达能力。这就是神经网络,尤其是深度神经网络的优势所在。
目标值为连续实数时,会学习得到一个回归器(regressor),目标值为离散值时该机器学习问题为分类。不过有时把回归和分类问题合在一起训练。
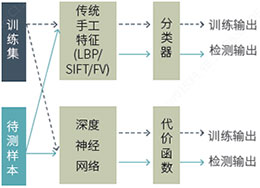
图4 神经网络相比手工设计特征具有更强的特征表现力
虽然理论界无法对深度神经网络如此强大的特征表达能力给出令人信服的理论推导,但是它在实践应用中的卓越表现极大刺激了它在各个领域的快速推广。ImageNet 2016 届大规模视觉识别挑战赛(ILSVRC-2016)结果刚刚公布,在各个比赛中获得第一名的团队采用的算法均是基于深度神经网络的。
神经网络结构
神经网络一般含有输入层、隐含层、输出层。
若含有多个或者很多个隐含层,则成为深度神经网络或者甚深神经网络,到底多少个隐含层算深,其实在学术界并没有严格的定义。
属于卷积神经网络(convolutional neural networks 或CNN)家族的各种结构神经网络主要用于处理网格结构数据,比如时间序列数据(音频)可以看成为按照一定时间间隔采样而成的1D 网格数据;图像可以看成由像素组成的3D 网格数据;视频可以看成是由按照时间采样的2D 图像组成的3D 网格数据;视频和光流可以是由2D 图像加1D 光流按照时间采样的4D 网格数据;等等。卷积神经网络主要的操作就是卷积,如图5 [3] 所示为2D 卷积原理示意图。卷积操作主要实现了稀疏交互(sparse interactions)、参数共享(parameter sharing)、等变表示(equivariantrepresentations)三种思想。卷积网络的一个层典型的具有三个阶段,首先是执行卷积操作产生一个线性激励(activation);然后是每个线性激励执行一个非线性激励函数,比如校正的线性激励(rectified linearactivation),这一阶段有时称为检测(detector)阶段;第三阶段,使用池化(pooling,或汇聚)操作进一步修改层的输出,即减少特征映射平面(feature map plane)中特征数目。
在安防领域大量应用的对象检测、对象跟踪、对象识别等应用都是基于卷积神经网络实现。
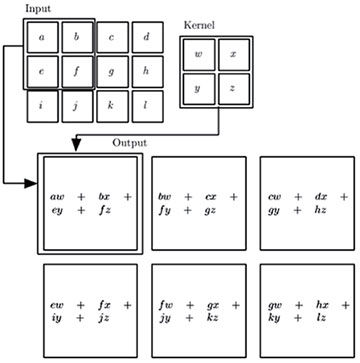
图5 2D卷积操作示意图
递归神经网络(Recurrentneural networks/ RNN)家族中各种结构神经网络主要用于处理序列化数据,所以一般认为递归神经网络对历史数据具有记忆性,即网络对当前输入计算输出时,既考虑当前的输入,由考虑历史输入。如图6所示,左边为未展开的递归神经网络原理示意图,右边的为展开(unfold)后的递归神经网络原理示意图。输入序列为x,输出序列为o,y 为目标输出,L为损失函数,h为内部状态,W 为网络连接权值。通过图6右侧看出,网络内部状态h 随着时间发生变化,不同于卷积神经网络,训练完毕后,网络状态处于静止状态,不会随着输入的变化而变化。
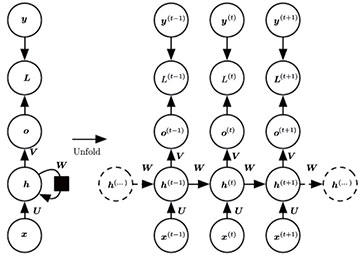
图6递归神经网络结构示意图
除了这两种主要的神经网络结构外,其实还有很多各种各样的网络结构,如图7[4] 所示。
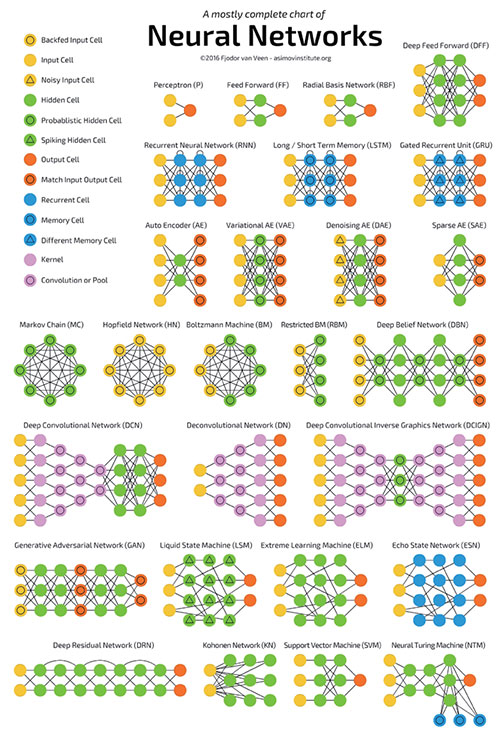
图7神经网络汇总[4]
神经网络发展现状
目前人类在脑科学方面对人脑的真正的工作机理还没有完全弄懂。深度神经网络,并不是严格意义上的类人脑计算,只是根据脑神经科学初期的研究成果,在一定程度上受到人脑信息处理机制的启发,模拟一些人脑细胞的工作构成网络,其本质上还是一些类似于支撑向量机、隐式马尔科夫链之类的机器学习模型。比如Facebook FIR 的LeCunYann 就曾经说过,卷积神经网络严格讲应为卷积网络(convolutional networks),之所以去掉“神经”二字就是为避免人们误解。但由于历史原因,以及一些学术论文的宣传目的,大都冠以“神经”二字,但目前在人类还未完全弄懂人脑全部工作机理的前提下,是不可能构造真正类似人脑一样的神经网络。
深度神经网络相比传统方法具有更强的特征表达能力,但它并不是万能的,也并不是适用于所有的问题。同时深度神经网络训练需要数据量足够大,若数据量不够大会导致过拟合,神经网络的优势就体现不出来。
但是在一些方面,深度神经网络确实有比人脑有更强大的地方,比如深度神经网络可以具有海量的内存存储能力,轻松把人脑无法记忆的许多数据存储起来进行检索。目前情况是,使用一个类型的数据集训练得到的深度神经网络不能对其他类型的数据进行应用,神经网络的功能单一,还无法跨领域学习;但是人脑可以在不同应用领域轻松的实现跨域联想,可以在数学领域借鉴音乐美术等艺术领域的一些思想火花。在围棋战胜李世石的AlphaGo 并不会下简单的象棋或者军棋,但是人脑可以轻松的进行类似思维切换。所以近期google 的Raia Hadsell 团队使用连接的神经网络结构实验这种可以实现思维切换的通用 (general artificialintelligence):进步神经网络(progressiveneural networks)[5],就是想打破这种功能限制,在神经网络的通用性上进行探索。如图8 所示,一个三列进步神经网络示意图,左边的两列(虚箭头)分别在任务1 和任务2 上进行训练,标a 的灰色框表示适应层(adapterlayers),附加上右边的第三列用于任务3,可以访问前面已经学习到的所有特征。
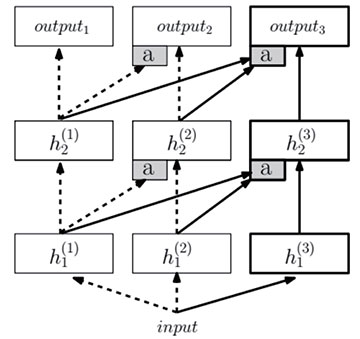
图8 进步神经网络
探索道路上人类才迈出了一小步,到底什么时候会真正探索到真理不得而知。如LeCunYann 就曾指出,现在大量使用的深度学习模型都是使用监督学习的方式,但是人脑的学习方式是无监督的。学者们在无监督学习的探索才刚刚开始。
虽然神经网络还处于发展初期,但表现出的超强能力,尤其自动驾驶、辅助驾驶方面的能力在全球各地有大量的实验以及应用。
比如最近美国国家交通部就正式发布针对自动驾驶汽车(self-driving cars/ automatedvehicles)的征求意见稿,美国前总统奥巴马还专门发表讲话[6] 把自动驾驶作为高新产业在美国的快速规范发展。自动驾驶汽车类似于机器人,集成了大多数的 技术,自动驾驶技术的发展会极大促进整个 技术的发展。
由于媒体和 厂商的肆意夸大宣传,导致非专业人们对深度神经网络产生很多误解,甚至引起恐慌,这些都是完全没有必要的。比如2016 年9 月,特斯拉在中国的一次车祸中,23 岁驾驶者驾驶一辆Model S 撞向路中间的道路清扫车致死。死者父亲接受采访时表示[7],他儿子一直信赖自动驾驶,因此在事故发生时并没有在观察路面情况。事故发生后,特斯拉在其中文网站中去掉了“自动驾驶”这个词。同时特斯拉表示,自动驾驶系统不是为了彻底取代驾驶员,打开自动驾驶后,驾驶员会受到语音和文字告警,迫使驾驶员将双手放在方向盘上,并注意路面情况。
但是某些媒体把这种需要驾驶员协助的自动驾驶吹嘘成无人驾驶,这极大误解了 技术,对技术的发展以及产业的发展都不会有好处,当达不到宣传的预期效果时,反而会给消费者产生不信任的印象。
目前已经应用或者打算应用的自动驾驶汽车案例(优步携手沃尔沃将在美国匹兹堡提供无人驾驶叫车服务,以及新创公司NuTonomy 的无人自驾计程车在新加坡纬壹科技城商业区投入运营)都必须在限制的场景。目前来看,还无法实现能够在各种场景中的真正的自动驾驶, 在某些领域很难达到人类水平的智能。
神经网络在安防行业中的应用现状
自从2012年AlexNet 发布后,和 相关的众多学科的研究人员把深度神经网络用于自己的研究领域,都取得了丰硕成果。安防行业主要与图像视频应用相关,其中最主要的研究方向有:图片或视频中的对象检测(object detection)、图片或视频中的对象定位(object localization)、基于视频的目标跟踪(object tracking)、基于图片或视频场景分类(scene classification)、基于图片或视频的场景解析(scene parsing)、基于图片或视频的目标行为识别(activityrecognition)。用于图像分类和检测应用的深度神经网络,AlexNet 后又出现了牛津大学的VGGNet,谷歌的GooLeNe(t Inception-v1、Inception-v2、Inception-v3、Inception-v4)以及后微软的ResNet(Resnet1、Resnet2),还有这两种结构结合后形成的Inception-ResNet、Inception-ResNet-v2。短短4年时间里,学术研究在积极探索着引领着网络结构的快速发展,同时产业界也积极把学术界的研究成果引入的各自的产品当中,并且结合产品应用的实际场景,对网络模型进行优化和增量训练,取得了卓越的效果。比如宇视科技的智能识别服务器IA8500-FA和IA9600-FS,视频摘要和视频浓缩服务器IA8500-VI、IA8800-VI、IA8800-VIM,都已经使用NVIDIA 公司新款GPU,同时配置卓越的深度神经网络结构,在各项检测和识别指标上在业界都达到了优秀水平。
在安防行业的分布式计算以及大数据挖掘方面,将来也会涌现出大量的创新与应用。对深度神经网络应用来说,网络结构与模型、实现代码已经变得不再重要。不同于传输的智能算法开发,单凭一家力量很难取得优异的结果。海量数据或者说大数据变得比网络结构和代码变得更重要!同时必须借助开源力量共同推进发展。所以在业界,尤其是学术以及行业领导者(google、facebook FAIR、美国纽约大学LeCunYann 团队、加拿大蒙特利尔大学Geoffrey E. Hinton 团队、百度的前吴恩达团队),纷纷开源自己的各种项目的代码,借助同行业的力量推动发展,同时建立在领域内的领导地位。
在安防行业应用展望
在安防行业,目前 算法使用最多的还是在视频图像领域,因为传统的安防企业的产品都是与视频图像相关。但对于有些业务应用来说,视频图像只是一小部分,还需要网络信息、通信信息、社交信息,等等。将来安防行业还需要以视频图像信息为基础,打通各种异构信息,在海量异构信息的基础上,充分发挥机器学习、数据分析与挖掘等各种 算法的优势,为安防行业创造更多价值。
参考文献
[1]https://en.wikipedia.org/wiki/Artificial_intelligence
[2]http://papers.nips.cc/paper/4824-imagenet-classification-with-deepconvolutional-neural-networks
[3]http://www.deeplearningbook.org/
[4]http://www.asimovinstitute.org/neural-network-zoo/
[5]http://arxiv.org/abs/1606.04671
[6]http://www.post-gazette.com/opinion/Op-Ed/2016/09/19/Barack-Obama-Self-driving-yes-but-also-safe/stories/201609200027
[7]http://m.cn.nytimes.com/technology/20160918/fatal-tesla-crash-in-china-involved-autopilotgovernment-tv-says/
 浙公网安备
33010802004032号
浙公网安备
33010802004032号

