面向视频监控应用的智能分析技术是一项覆盖图像处理、计算机视觉、机器学习、概率统计、深度学习、并行计算与GPU 优化等多个领域的应用技术。这些技术领域本身在不断的发展当中,有些发展还不是很完善。这必然导致视频监控中的智能分析技术也处于不断发展的态势。尤其进入2010 年代,随着互联网数据量爆炸式的增长,催生大数据和云计算技术的出现,尤其是把二者结合的深度学习技术发展的如火如荼,在图像识别、视频识别领域的应用带来了革命性的更新。
遥想2005 年前后,视频监控领域智能分析技术刚刚起步,采用传统图像处理技术和基于手工设计特征训练分类器,效果和性能不尽人意,同时客户对智能分析技术没有客观的认识,有的盲目乐观,也有的盲目悲观,智能分析产品举步维艰。经过10 年的技术发展和市场培育,客户对智能分析具有较为客观的认识。智能分析应用从视频监控行业的辅助功能发展成为安防行业的本质需求,这与智能分析技术的高速发展分不开的。相信在未来的一段时间内,智能分析技术的发展更加迅速,在视频监控行业的应用形式和产品形态也会发生很大的变化。
本文从传统目标跟踪算法和最新的深度卷积网络算法两个角度来展现智能分析技术的最新的发展。
CMT 跟踪算法
CMT 跟踪算法主要由WACV(WinterConference on Applications of Computer Vision)2014 会议上的《Consensus-basedMatching and Tracking of Keypoints forObject Tracking 》和CVPR 2015 会议上的《Clustering of Static - Adaptive Correspondencesfor Deformable Object Tracking 》构成 。并且在W A C V 2014 获得最佳论文奖项(Best PaperAward)。由奥地利技术学院的Georg Nebehay提出。

(图1)CMT 跟踪算法流程框图
CMT 跟踪相比之前的TLD 算法性能提高许多。可以认为是TLD 之后的下一代跟踪算法。TLD 算法使用整体模型进行跟踪。CMD跟踪的基本思路是能够不断检测物体特征,并通过多种手段对检测到的物体特征进行反复匹配验证,实现高准确度跟踪,同时计算资源又很节省,适合在前端相机段运行。
CMT 算法中把跟踪目标称为前景,其他部分为背景,前景用包围框框住。若当前帧为第N 帧,前一帧为N-1 帧。CMT 跟踪算法流程如图1 所示。一般的跟踪算法和背景建模与前景检测算法类似一般运行在前端设备,由于前端相机计算资源有限,不太会运行复杂的机器学习算法。由如图1 可见,整个CMT 流程由光流算法、KNN 聚类和层次聚类构成,但是巧妙之处在于进行对当前第N 帧和前一帧第N-1 帧的光流法得到的跟踪关键点,以及有特征点检测得到的特征点,两种点进行反复验证融合,大大提高鲁棒性。
CMT 算法首先对首帧检测FAST 特征点及其BRISK 特征描述,其中包括前景框中的特征点。然后把前景框的特征点与背景部分的特征分为两类保存,并求取前景框中的两两特征点之间的相对距离和相对角度。对后续的每一帧继续检测FAST 特征点及其BRISK 特征描述。对当前帧(从第二帧开始)中使用BRISK 特征描述在前一帧前景特征点进行KNN 聚类,从特征点的角度对前景点进行验证。
并对后续的每一帧(从第二帧开始)的前景框内的关键点,进行前向光流估计(N-1 → N),对得到的光流点再进行后向光流估计(N → N-1),经过双向验证去掉假的前向光流估计。这样对光流跟踪和特征描述聚类两个角度的跟踪点进行融合。
前景目标在摄像机场景中运动的过程中,物距发生变化,由透视成像原理得知,前景目标成像尺寸会发生变化,同时也会发生旋转变化。CMT 跟踪算法考虑到了这两种变化。所以在首帧时已经记录了前景框内所有关键点两两点之间的距离矩阵和相对角度矩阵。在后续的每一帧时,也同时距离当前帧前景框内所有点两两点的距离和相对角度。然后根据中值算法,计算当前前景点相对首帧前景的缩放尺寸和旋转角度。
然后根据相对首帧的缩放尺寸和旋转角度中值,对每个特征点进行进行投票,并采用层次聚类的方法选取最大的类也就是最一致的变换点,并把变换点转换回特征点,得到在当前帧上的有效特征点。并得到当前前景框的中心点估计。
然后使用估计得到的中心点,在当前帧内,再从特征点的角度相对首帧的前景点变换后的点进行KNN 聚类,进一步验证当前关键点的准确性。
CMT 跟踪算法减小轻便,不依赖模型学习,准确率高,适宜在前端相机进行行人跟踪、车辆图像属性块跟踪,大大提高产品性能,为其他算法模块提供有效资源。
宇视结合不同智能相机实际应用场景,以CMT 算法为指导,对现有跟踪算法进行改进,取得了更优秀的效果,把相机的智能分析功能提高到更高的一个层次。
深度卷积网络
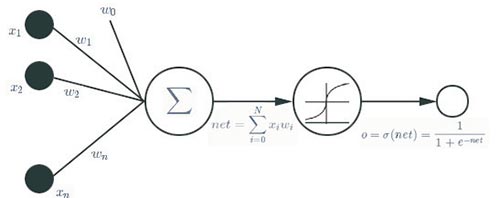
卷积网络(Convolutional Networks)又常称为神经网络(Neural Networks) 或者卷积神经网络(Convolutional NeuralNetworks,CNN)。多层卷积网络称之为深度卷积网络。卷积网络最基本的运算单元称为神经元,如图2 所示。正如深度卷积网络之父Yan LeCun 指出的卷积网络严格来说不能称之为神经网络,同样神经元运算单元也不是神经科学意义上的神经元。其实到目前为止,人类还未真正弄清楚人脑的工作机理,但是在一定程度上人们知道一个大脑皮层神经元的工作过程。
(图2)神经元

(图3)大脑皮层神经元
如图3所示,神经元具有一个轴突(axon)分支,同时有一个收集来自其他神经元输入的树突树(dendritic tree)。轴突通常在突触(synapses)和树突树进行通信。有一个轴丘(axon hillock),每当足够的电荷流出突触,以使得细胞膜去极化后,就会生成峰值,轴突上的激励峰值会注入电荷到突触后的神经元。
所谓深度卷积网络中的神经元只是大脑皮层神经元的近似。模仿大脑神经元层层连接成网状的结构,把一个个神经元计算单元层层排列进行连接,就构成了所谓的深度卷积网络。
卷积神经网络并不是个新算法。在20 世纪50 年代就已经出现,后来到80 年代出现了使用CNN 进行数字识别,但是由于训练时间过长,仍然没有大量使用。
CNN 再次引入注目是Geoffrey E. Hinton(CNN 的另一个发明者) 及其弟子AlexKrizhevsky 在NIPS2014 会议上发表《ImageClassification with Deep ConvolutionalNeural Networks》,首次使用深度卷积神经网络在 LSVRC-2010 ImageNet(2010 年度大规模视觉识别挑战赛(Large Scale VisualRecognition Challenge)数据集ImageNet)数据集上进行通用目标的检测,其TOP-1 错误率和TOP-5 错误率比先前的基于手工设计特征的最好的方法都要优秀很多很多。同时该论文使用GPU 进行加速,大大缩短模型训练时间,提高CNN 训练的可行性。其实CNN的再次风靡,不仅是由于近几年GPU 加速技术的突飞猛进,大大缩短CNN 的训练时间,同时由于移动互联网和智能手机拍照功能的增强,可以轻易获得百万级别的训练样本,所以说是现在具备了训练CNN 的客观条件。
尤其是在视频监控行业,大量部署的智能相机24 小时不间断的采集车辆、行人等等各种图片视频信息。海量视频图片信息对采用CNN 算法提供了天然的优势资源。
(图4)LeNet
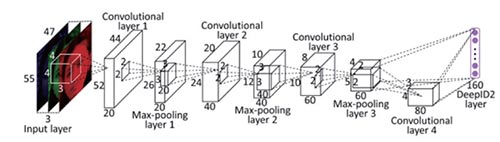
(图5)DeepID2
我们知道深度神经网络属于机器学习(Machine Learning)学科范畴,机器学习科学除了CNN 之外还包括聚类算法,SVM 算法、深度波兹曼机器、深度递归网络,深度信念网络等。这些算法应用在视频监控领域的智能分析技术的方方面面,它们的训练都与海量样本有关。
机器学习在视频监控行业的应用主要有通用目标检测、定位、识别,通用目标包括车辆、车型、车标、各种非机动、行人等,还可以是各种目标的属性检测,比如车身颜色、行人发式或者衣服属性识别。传统智能分析技术中的背景建模与前景检测、运动目标检测、运动目标跟踪等传统应用也使用机器学习中的各种算法,比如聚类算法、光流算法、各种特征描述符等。
在最新的Garner2015 新兴技术发展周期报告上(图6 和图7),大数据(Big Data)在2015 年的炒作周期表上已经看不到它了,2014 年的炒作周期表上已经表明它正走向低谷。这可能意味着最后关注的大数据相关技术已经不是一种新兴技术,它们已经用于实践当中。机器学习在今年的周期表中首次出现,但是已经越过了膨胀预期的顶峰,取代了大数据技术。
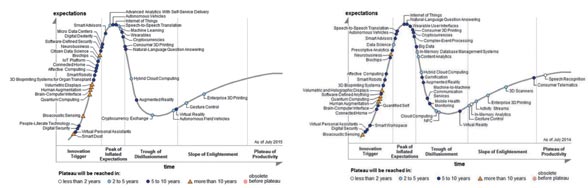
(图6)Gartner 2015新兴技术发展周期 (图7)Gartner 2014新兴技术发展周期
在CVPR2015会议召开之际,文章《Deep down the rabbit hole: CVPR 2015 and beyond》中作者认为在CVPR2015会议上,若提交的论文没有采用DNN(Deep NeuralNet works),不把ConvNet(深度卷积网络开源库,深度卷积网络(Deep Convolutional Networks)是一种主要的DNN)作为比较基准,很难被采用。作者同时把CNN的之父YannLeCun的地位提高的笛卡尔坐标系在数学界的高度(图8)。可见DNN在计算机学习领域的影响之大。

这表明在今年以及未来的一段时间里,机器学习相关技术会吸引更过的科研机构投入其中,结合愈来愈丰富的海量数据,尤其海量图片和视频数据,一定会在视频监控领域,发掘出更多更优秀的算法出来,对视频监控行业产生更深的影响,这将极大提升视频监控领域中的许多智能分析技术的升级换代,给客户带来更高的准确度和性能。比如最近微软云服务azure,以及阿里云服务,还有开源云计算平台Spark,都在其中添加了GPU加速的机器学习功能,这会极大促进机器学习云服务的推广与普及。虽然目前在视频监控行业还未看到类似的使用GPU加速的机器学习云服务,但相信在不久的将来,会在监控行业出现这样的服务项目,客户需要服务时,只需要把图片视频上传到云端,云端分布式GPU深度学习模块很快的就返回具有可视化功能的结果显示,各个派出所级别的客户没有必要再单独购买智能分析设备。
为更好的迎接机器学习,尤其是深度学习,以及GPU加速对视频监控领域的智能分析技术带来的深刻变革,专门成立了机器学习研究院,专注于在视频监控领域,机器学习结合传统智能分析技术,深入研究下一代智能分析算法以及产品形态。
目前,宇视已经把机器学习算法深入应用到车辆检测与识别、车辆各种属性检测与识别、人体身份一致性识别等等多个产品中,致力于为客户带来更高品质的智能体验。
 浙公网安备 33010802004032号
浙公网安备 33010802004032号

