顾名思义,以图找图就是你定一张图片,搜索引擎帮你搜索相同或相似的图片。以下是在tineye上搜索美国派演员艾丽森·汉尼根的结果:
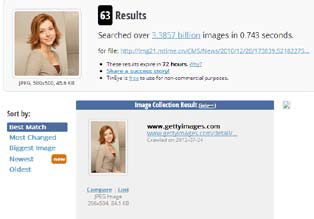
类似的更神奇的,甚至可以找出照片的拍摄背景。
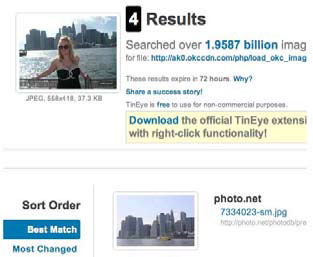
这种技术的原理是什么?计算机怎么知道两张图片相似呢?
其实方法有很多。我们先来了解一个快速算法,就能达到基本的效果。这个关键技术叫做"感知哈希算法"(Perceptualhash algorithm),它的作用是对每张图片生成一个"指纹"(fingerprint)字符串,然后比较不同图片的指纹。结果越接近,就说明图片越相似。

下面是一个最简单的实现:
第一步,缩小尺寸。
将图片缩小到8x8的尺寸,总共64个像素。这一步的作用是去除图片的细节,只保留结构、明暗等基本信息,摒弃不同尺寸、比例带来的图片差异。
第二步,简化色彩。
将缩小后的图片,转为64级灰度。也就是说,所有像素点总共只有64种颜色。
第三步,计算平均值。
计算所有64个像素的灰度平均值。
第四步,比较像素的灰度。
将每个像素的灰度,与平均值进行比较。大于或等于平均值,记为1;小于平均值,记为0。
第五步,计算哈希值。
将上一步的比较结果,组合在一起,就构成了一个64位的整数,这就是这张图片的指纹。组合的次序并不重要,只要保证所有图片都采用同样次序就行了。

得到指纹以后,就可以对比不同的图片,看看64位中有多少位是不一样的。在理论上,这等同于计算"汉明距离"(Hamming distance)。如果不相同的数据位不超过5,就说明两张图片很相似;如果大于10,就说明这是两张不同的图片。
这种算法的优点是简单快速,不受图片大小缩放的影响,缺点是图片的内容不能变更。如果在图片上加几个文字,它就认不出来了。所以,它的最佳用途是根据缩略图,找出原图。
实际应用中,往往采用更强大的pHash算法和SIFT算法,它们能够识别图片的变形。只要变形程度不超过25%,它们就能匹配原图。这些算法虽然更复杂,但是原理与上面的简便算法是一样的,就是先将图片转化成Hash字符串,然后再进行比较。
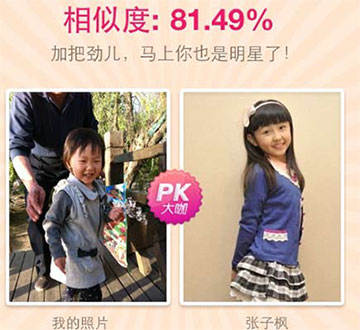
另外类似的软件还有“百度魔图”的明星脸PK,我用我自己女儿的照片做了实验,结果显示我女儿与一位童星有80%的相似度,虽然她们年龄有差距,但至少她们都是小女孩,并且她们有共同的特征,小眼睛,小脸盘,尖下巴,小酒窝,并且她们都正在笑。
那么百度魔图是怎么做到的?凭我的猜测,可能利用了“大数据”,大数据不仅是软件,它更是一个解决问题的思路,一个“将一个复杂作业变成成千上万个简单动作,然后让一群简单的节点并行完成这些动作”的思路”。百度魔图就是利用了这个思路,它将一个智能比对的复杂算法分解成若干个简单特征算法:长脸or圆脸、大眼睛or小眼睛、黑人or白人、带不带眼镜、长不长胡子、是笑还是哭...等等,可能有一百多种,它将这些算法分别在你的脸上和明星的脸上进行计算(明星的脸事先已经计算好,将特征数据存在数据库),然后将你的特征集合和明星的特征集合利用分布式计算进行逐个比对,算出和你匹配项最多的那张明星脸(就是相似度,90%、80%、70%...)。
大数据的好处是,你可以利用海量的资源完成这件事情,我们知道图像识别算法是非常消耗资源的。上面的第一个算法例子还只是单机的实现,那么下面的百度魔图就可以利用分布式的计算提高准群率,只要不断的增加特征识别的基本算法,然后增加计算机源完成它,理论上就可以以一种无限接近方式去搜图了。
 浙公网安备
33010802004032号
浙公网安备
33010802004032号

