软件发展主要是两件事:简单性和模块化,简单是简化情况以解决问题,模块则是为了分工合作。大数据发展完美诠释了这个过程。
大数据,是在网页检索中发展起来的,其中关键是 Google,它奠定了大数据技术的基础。
网页检索,海量数据,面临很多挑战。
海量网页存储,但现有存储系统,“贵”、“不易扩展”、“数据存储还不可靠”(注:Raid5重建,慢,且重建过程中坏盘,则就无法恢复了)。
Google据此,推出GFS分布式文件系统,它有如下特点:
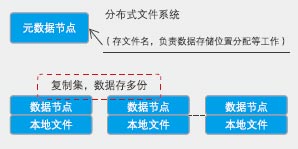
■ 独立元数据节点。
■ 不要Raid,多机存多份(使用廉价服务器群,并认为故障是常态)。
■ 不删除,不修改,只添加和覆盖(一次写,多次读)。
海量网页需要建立索引,但现有数据库写入性能低,检索起来慢。
分析,大数据下的读写模型和传统数据库有差异,传统数据库模型,大量时间在硬盘寻址上,所以Google推出BigTable非关系型数据库,它有如下特点:
■不要多表 。
■不要回滚 。
■不要格式校验 。
■不要触发器 。
■批量读数据,减少磁头寻址时间。
■数据容忍丢失,大量缓存,排好序一次写。
■多费些硬盘,对关键值Hash,快速查找 。
网页词频分析,需分布式计算,但编程复杂。
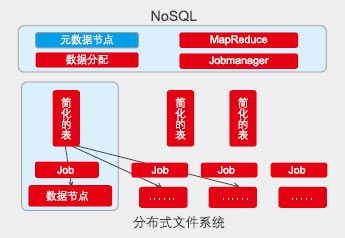
分析,计算过程中,大部分运算是矩阵运算,矩阵运算可分解为小矩阵乘积。据此,Google推出MapReduce计算框架,它简化计算模型,只解决80%的场景问题,过程抽象如下:
■ Map过程:“数据分N份,每个数据独立映射”,这部分可高度并发。
■ Reduce过程:数据集数据进行合并运算。
■ 分布式调度框架:调度原则为“移动计算比移动数据更便宜”。
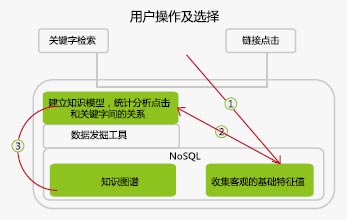
检索中,用户输入和结果之间,是先知经验,有各种方法可定义经验,Google的方法是“知识图谱”,观点是“数据足够,通过常用的统计,足可模拟出大部分人的先知经验”。
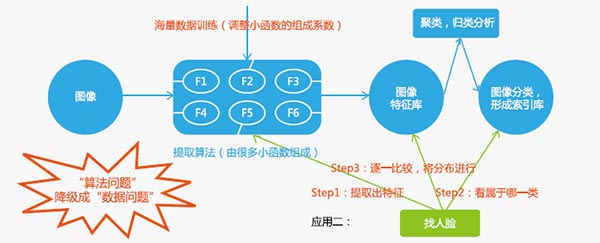
检索中,多媒体理解的需求越来越多,Google提出的理念是:“数据比算法重要,如训练数据合理且充分,简单的模型也可无限逼近现实”,近年来,语音和智能识别的突破方向,也说明了这种趋势。
大数据的发展历史,给我们很多启示:“简单拿来主义是不够的,更重要的是,要以问题出发,在行业理解的基础上,模型充分简单化,并在过程中,要有打破传统思维的勇气”。
 浙公网安备 33010802004032号
浙公网安备 33010802004032号

